https://colab.research.google.com/drive/10PjnrRKM2zR2v6xruyMoVq9EkaFdRKFn?usp=sharing
K-Nearest Neighbors.ipynb
Colaboratory notebook
colab.research.google.com
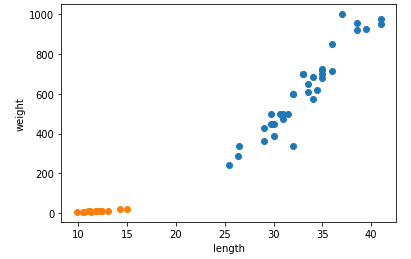
요약
1. 데이터 준비/ 전처리 (2차원 리스트로 만들기)
2. 정답 데이터 준비 (이진분류에서는 보통 정답인 대상의 데이터를 1, 그 외 정답인 아닌 데이터는 0으로 표현함)
3. 사이킷런의 K - 최근접 이웃 알고리즘 모델 클래스명은 KNeighborsClassifier() 이다.
4. K-최근접 이웃 알고리즘의 fit() 메서드는 두 매개변수로 훈련에 사용 될 특성과 정답 데이터를 전달한다.
predict()메서드는 사이킷런 모델을 훈련한 뒤, 예측 할 때 사용하는 메서드이다. 특성 데이터 하나만 매개변수로 받는다.
score() 메서드는 훈련된 사이킷런 모델의 성능을 측정한다. 두 매개변수로 특성과 정답 데이터를 전달한다.
'AI > 머신러닝' 카테고리의 다른 글
| K-최근접 알고리즘02 (훈련세트/테스트세트) (0) | 2023.01.24 |
|---|---|
| 머신러닝 알고리즘 분류 (지도학습/비지도학습/강화학습) (0) | 2023.01.24 |

