1. 데이터수집의 3가지 유형
일반적인 데이터수집에는 3가지 유형이 있다.
- DB(데이터베이스)에 직접 접근하여 데이터를 가져오기
- 웹 API를 통하여 데이터를 가져오기
- 웹 스크래핑(크롤링)를 통하여 필요한 데이터 가져오기
데이터베이스에 직접 접근하여 데이터를 가져와도 되지만, 회사의 보안 정책등에 의해 직접 접근 할 수 없는 경우가 많다. 이럴 경우 웹API나 웹스크래핑으로 필요한 데이터를 가져와 수집하게 된다.
2. 웹 API 란?
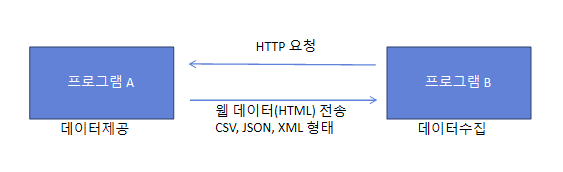
- API(Application Programming Interface)
- 두 어플리케이션이 데이터를 주고 받기 위한 규칙
- 웹 API는 HTTP 프로토콜을 사용하여 웹 서버측(프로그램A)에서 클라이언트(프로그램B)에게 데이터를 전달하는 방식
- 웹 API의 사용은 데이터를 제공해주는 웹 서버측에서 가이드(API문서)를 같이 제공한다.
- 일반적으로 데이터는 CSV, JSON, XML 3가지 유형으로 제공된다.
3. JSON 이란?

{
"이름": "홍길동",
"나이": 55,
"성별": "남",
"주소": "서울특별시 양천구 목동",
"특기": ["검술", "코딩"],
"가족관계": {"#": 2, "아버지": "홍판서", "어머니": "춘섬"},
"회사": "경기 수원시 팔달구 우만동"
}
## 위키피디아 JSON 예제- JSON (JavaScript Object Notation)
- 키(Key) : 값(Value)
- 데이터를 수집하는 경우 JSON을 만날 확률이 매우 높음
- JSON은 파이썬의 딕셔너리와 리스트를 중첩해 놓은 형태
- 자바스크립트 언어를 위해 만들어졌지만 현재는 범용적인 텍스트 기반의 포맷으로 사용됨
- 대부분의 프로그래밍 언어는 JSON 형태의 텍스트를 읽고 쓸 수 있음
# 딕셔너리(Dictionary)
# Key(키):Value(값)
dic = { "key1": "val1", "key2": "val2", "key3":"val3" } # 딕셔너리 선언
print(dic)
# 딕셔너리 요소에 접근할 때는 리스트처럼 대괄호[] 입력
print(dic["key2"]) # 리스트는 인덱스지만 딕셔너리는 요소는 키 값으로 접근함
dic_2 = { "ary" : [0,1,2,3] ,"ary2" : [4,5,6,7] }; print(dic_2) # 키에 대한 값으로 리스트를 넣어도 됨
dic_2["ary"] = [8,9,10,11]; print(dic_2) # 딕셔너리 키 값을 변경
dic_2["ary3"] = [1,2,3,4]; print(dic_2) # 새로운 키와 값 추가
del dic_2["ary"]; print(dic_2) # del 키워드를 사용하여 키와 값 삭제- 딕셔너리는 키를 기반으로 여러 자료를 저장하는 자료형
- 키는 딕셔너리 내부에서 값에 접근할 때 사용됨
- 값은 딕셔너리 내부에 있는 각각의 내용을 의미함
# JSON 데이터 다루기
# JSON은 파이썬의 딕셔너리와 리스트를 중첩해 놓은 것과 비슷
import json # json 패키지
dic_str = json.dumps(dic, ensure_ascii=False) # ensure_ascii 매개변수를 False로 하여 한글출력에 문제가 없도록함.
print(dic_str)
print(type(dic_str)) # str형식인지 데이터타입을 확인해봄- 파이썬 객체를 JSON 형식에 맞는 텍스트로 바꿀 때 json.dumps() 함수를 사용
- josn.dumps() 함수는 아스키 문자 외의 다른 문자를 16진수로 출력하기 때문에 한글을 볼 수없다.
# json.loads() 함수 사용 json 문자열 -> 파이썬 딕셔너리
dic2 = json.loads(dic_str) #dic_str을 다시 파이썬 딕셔너리로 바꿈
print(type(dic2)) # 잘바뀌었는지 데이터타입을 확인
print(dic2["key1"])
dic3 = {'book_name':'EMBEDDED RECIPES', 'author': ['히언','이은경'],'publisher' : '스노우북','year':'2023'}
print(type(dic3))
print(dic3['author'][0]) # 딕셔너리의 리스트 확인
dic_str = json.dumps(dic3, ensure_ascii=False)
print(type(dic_str))- API로 JSON 문자열을 받으면 파이썬에서 사용할 수 있도록 파이썬 객체로 변환해야한다.
- json.loads()함수를 사용하면 JSON문자열을 파이썬 객체로 변환 할 수있다.
- JSON 배열의 형태는 파이썬 리스트로 변환 할 수있다.
#json 문자열을 데이터프레임으로 변환: read_json() 함수, DataFrame()함수
import pandas as pd
pd.read_json(dic_str)
pd.DataFrame(dic3) # 파이썬의 리스트를 데이터프레임으로 변환
- 판다스는 JSON문자열을 읽어서 데이터프레임으로 변환하는 read_json()함수를 제공한다.
4. XML 이란?


- eXtensible Markup Language
- XML은 컴퓨터와 사람이 모두 읽고 쓰기 편한 문서 포맷을 위해 고안
- XML은 엘리먼트(element)들이 계층 구조를 이루면서 정보를 표시
- < > 기호로 시작해서 < / >기호로 끝남
- 시작태그와 종료태그의 이름은 같아야함
- <book>은 <name>, <author>, <year> 들의 상위 엘리먼트로 써 부모 엘리먼트, 부모 노드라고 함
- <name>, <author>, <year> 들은 <book>의 하위 엘리먼트로 써 자식 엘리먼트라고 부름
- <book> 엘리먼트를 여러개 포함하는 경우 부모 엘리먼트는 s를 붙여 <books>라고 표현
- 태그 이름은 특수 문자와 공백 문자를 포함 할 수없고 '-', '.' 와 숫자로 시작할 수 없음
# XML
x_str = """
<book>
<name> 임베디드 스케치</name>
<author> 히언 </author>
<year> 2023 </year>
</book>
"""
# 파이썬에서 기본제공되는 XML 패키지
import xml.etree.ElementTree as et
book = et.fromstring(x_str) # x_str 문자열을 XML로 변환
print(type(book))
print(book.tag) # 태그 읽기
book_ = list(book) # 리스트 명시적 형변환
print(book_) # <book> 구조
name, author, year = book_
print(name.text)
print(author.text)
print(year.text)
# findtext() 메서드 사용 자식 엘리먼트 탐색
# 해당하는 자식 엘리먼트를 탐색하여 자동으로 텍스트로 반환
name = book.findtext('name')
author = book.findtext('author')
year = book.findtext('year')
print(name); print(author); print(year)
# 여러개의 자식 엘리먼트 확인
x2_str = """
<books>
<book>
<name>임베디드레시피</name>
<author>히언</author>
<year>2023</year>
</book>
<book>
<name>혼자공부하는 파이썬</name>
<author>박해선</author>
<year>2023</year>
</book>
</books>
"""
books = et.fromstring(x2_str) # from 함수를 사용하여 부모 엘리먼트를 확인
print(books.tag) # 부모 엘리먼트 사용
# findall()메서드는 동일한 이름을 가진 여러 개의 자식 엘리먼트를 찾을 때 사용
for book in books.findall('book'):
name = book.findtext('name')
author = book.findtext('author')
year = book.findtext('year')
print(name); print(author); print(year); print();
# 판다스 1.3.0 버전 부터 read_xml 사용가능
print(pd.__version__) # 판다스 버전 확인
pd.read_xml(x2_str)- XML 패키지는 XML 문서를 읽고 쓸 수 있는 라이브러리를 제공
- xml.etree.ElementTree 모듈의 fromstring() 함수로 파이썬의 문자열을 XML로 변환
- fromstring() 함수가 반환하는 객체는 ElementTree 모듈 아래에 정의된 Element 클래스의 객체
- findtext() 메서드로 자식 엘리먼트를 확인 할 수 있음
- findtext() 메서드를 사용하면 해당하는 자식 엘리먼트를 탐색하여 자동으로 텍스트를 반환
- 여러 개의 자식 엘리먼트를 확인하려면 findall() 메서드와 for문을 함께 사용
- 판다스 1.3.0 버전 부터 read_xml() 함수 사용가능, 판다스 버전 확인 후 read_xml() 함수를 사용

https://colab.research.google.com/drive/1mkrtc1v4BC-DIC6wQizBV1tNgOyxPDdG?usp=sharing
python_Data_collection.ipynb
Colaboratory notebook
colab.research.google.com
'임베디드 AI > 데이터분석' 카테고리의 다른 글
| 회원별 당구 에버리지 데이터 분석 (feat. Pandas) (3) | 2024.09.16 |
|---|---|
| 데이터프레임_도서관대출데이터 (0) | 2023.04.16 |
| 데이터분석 파이썬 필수 라이브러리 (0) | 2023.04.15 |


