1. Data 분석 동기

Python과 데이터분석을 활용하지 않은지 꽤 오래되어서 Pandas와 Matplotlib라이브러리 사용법을 잊어버리고 있었다...
최근에 취미생활로 활동 중인 당구 동호회에서 회원별 에버리지 Data를 수집하고 있는데 이를 활용하여 그동안 잊고 지냈던 Python 감각을 일깨워 주고자 했다. 임베디드 영역에서도 온 디바이스 AI 열풍으로 AI 관련 기술을 익히는 건 아깝지 않다고 생각한다. (데이터분석은 AI 알고리즘을 활용하기 위해 매우 필요한 기술스택이다.)
2. 원천 데이터 xlsx 파일을 csv 파일로 변환하기
pip install pandas openpyxl # 당연히 Pandas는 설치되어야 한다.import pandas as pd
avg_file = "AVG_Data.xlsx" # 원천 xlsx 데이터
# 원천 xlsx 파일을 판다스에서 불러와 csv로 변환하여 저장한다.
df = pd.read_excel(avg_file)
df.to_csv("AVG_Data.csv", index=False)
# index=False 옵션은 CSV 파일에 데이터프레임의 인덱스(행 번호)를 포함하지 않도록 설정하는 옵션(1) csv 파일을 선택해야하는 이유
- CSV 파일은 순수하게 데이터를 저장하는 형식이라 크기가 훨씬 작고 가볍다.
- CSV 파일은 모든 프로그래밍 언어에서 쉽게 해독할 수 있도록 호환성이 보장된다.
- CSV 파일은 읽는 속도가 xlsx 파일에 비해 빠르다
- 단순한 데이터를 분석할 경우 CSV 파일이 더 유리하지만, 분석할 데이터에 서식이나 수식이 포함된 경우에는 xlsx 파일 형식을 사용해야 한다.
(2) Pandas 주요 메서드
- read_excel() : xlsx 파일을 불러오는 메서드
- to_csv() : 파일을 csv 파일로 변환하여 저장한다.
3. Pandas 데이터프레임 구조로 변환하기
df = pd.read_csv("AVG_Data.csv", header=None) # Pandas로 csv 파일 read
#### 전처리 과정 ####
df.drop(0, inplace=True) # 첫 번째 행을 삭제하고 인덱스를 초기화
# 선수이름이 포함되어 있는 열은 개인정보를 위해 수정한다.
df.iloc[0, 1:] = ['선수' + str(i) for i in range(1, len(df.columns))]
# 1행의 첫 번째 열은 그대로 두고, 2번째 열부터 수정
df.head()
(1) 데이터프레임 구조 (복습)
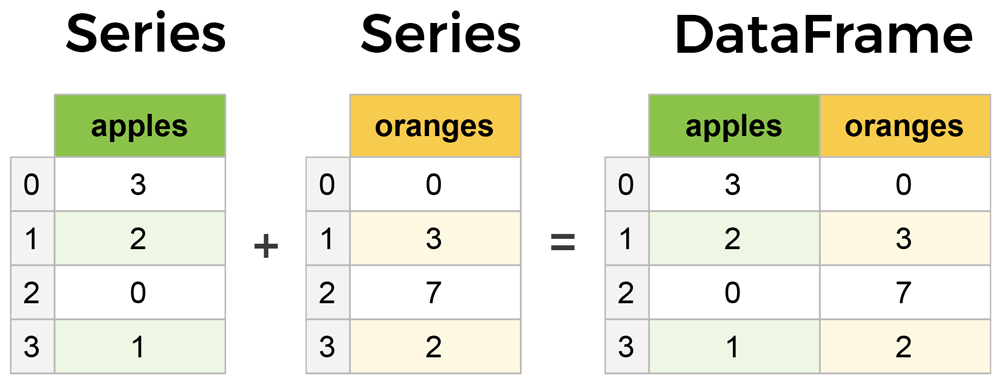


(2) Pandas 주요 메서드
- read_csv() : csv 파일을 불러오는 메서드
- drop() : 행이나 열을 삭제
- loc() : 라벨 기반 인덱싱(범위지정) / 라벨 기반 인덱스
- iloc() : 위치 기반 인덱싱(범위지정) / 정수 기반 인덱스
4. 각 회원별로 몇개의 데이터를 가지고 있는가? (count)
df_cnt = df # 문제해결을 위한 새로운 Data 프레임 생성
df_cnt.drop([1,2,3], inplace=True) # 분석에 불필요한 행과 열을 삭제
df_cnt.drop([0], axis=1, inplace=True)
df_cnt.reset_index(inplace=True) # 데이터 프레임 인덱스 초기화
df_cnt.head()
import matplotlib.pyplot as plt
from matplotlib import font_manager
df_s = df_cnt.count() # 각 열의 유효한 데이터 개수 계산 (count 메서드는 시리즈로 반환한다.)
df_s = df_s.drop(df_s.index[0]) # 인덱스 0 을 제거 (헤더가 의미 없음)
df_s.plot(kind='bar', color='skyblue') # 막대 그래프로 데이터를 표시
plt.title('Count')
plt.xlabel('Player')
plt.ylabel('Games')
plt.show()
(1) Pandas 주요 메서드
- count() : 각 열의 유효한 데이터 수를 계산한 결과를 시리즈(Series)로 반환한다.
- reset_index() : 데이터프레임의 인덱스를 초기화
- plot() : 데이터프레임에서 다양한 유형의 그래프를 그릴 수 있는 도구 (Matplotlib과 통합되었다.)
(2) Matplotlib 에서 지원되는 차트, 그래프
- 'line': 꺾은선 그래프 (기본값)
- 'bar': 세로 막대 그래프
- 'barh': 가로 막대 그래프
- 'hist': 히스토그램
- 'box': 상자 그림 (box plot)
- 'kde': 커널 밀도 추정(KDE)
- 'area': 면적 그래프
- 'pie': 파이 차트
- 'scatter': 산점도 (이 경우 x와 y 인수를 지정해야 함)
5. 기술통계 (discribe) - 평균, 최대, 최소, 표준편차, 25%, 50%, 75% 구하기
(1) 기술통계란?
- 테크니컬한 어떤것을 의미하는게 아니라 자료의 내용을 압축하여 설명하는 방법을 의미한다.
- 다른말로는 요약 통계라고도 한다.
(2) Pandas 통계 (discribe 메서드)

[ 숫자형 통계 ]
- count : 누락된 값을 제외한 데이터 갯수
- mean : 평균
- std : 표준편차
- min : 최소값
- 50% : 중앙값
- 25% : 25% 지점
- 75% : 75% 지점
- max : 최대값
[ 범주형 통계 ]
- count : 누락된 값을 제외한 데이터 갯수
- unique : 고유 값의 수
- top : 가장 자주 나타나는 최빈값
- freq : top으로 표시된 값이 나타나는 빈도수
df_discribe = df_cnt
df_discribe = df_discribe.drop(df_discribe.columns[0], axis=1)
df_discribe.head()
df_discribe = df_discribe.astype(float).describe()
# 왜 인진 모르겠지만 범주형으로 인식되서 강제적으로 float 형변환...
print(df_discribe)
# 필요한 통계량만 추출 (mean, std, min, 25%, 50%, 75%, max)
stats = df_discribe.loc[['mean', 'std', 'min', '25%', '50%', '75%', 'max']]
# 각 통계량에 다른 색상을 지정
colors = ['red', 'blue', 'green', 'purple', 'orange', 'brown', 'pink']
# 막대그래프 그리기
stats.T.plot(kind='bar', color = colors, figsize=(20, 10))
# 그래프 제목과 축 이름 설정
plt.title('Summary Statistics')
plt.ylabel('Values')
plt.xlabel('Player')
plt.xticks(rotation=0)
plt.show()
# 꺽은선 그래프 그리기
stats.T.plot(color = colors, figsize=(20, 10))
# 그래프 제목과 축 이름 설정
plt.title('Summary Statistics')
plt.ylabel('Values')
plt.xlabel('Player')
plt.xticks(rotation=0)
plt.tight_layout()
plt.show()
https://colab.research.google.com/drive/1ac_2Jr9FedhGG6Pydjf0yDhl-odaOrhy#scrollTo=3kWOzi_oCB9D
Google Colab Notebook
Run, share, and edit Python notebooks
colab.research.google.com
'AI > 데이터분석' 카테고리의 다른 글
| 웹API (JSON, XML) (0) | 2023.04.17 |
|---|---|
| 데이터프레임_도서관대출데이터 (0) | 2023.04.16 |
| 데이터분석 파이썬 필수 라이브러리 (0) | 2023.04.15 |


